
The wave of generative AI is moving from the cloud to the end side, and end side AI is the key to the popularization of generative AI.
However, end devices are generally more sensitive to power consumption. How to ensure low power consumption while providing sufficient AI performance?
Arm’s clever trick is to directly embed dedicated matrix acceleration units into the CPU. James McNiven, Vice President of Product Management at Arm Terminal Business Unit, said, “It enables end-to-end AI inference to be completed directly on the CPU, significantly reducing data transmission latency between CPUs, NPUs, or GPUs. ”
In September of this year, Arm released the Arm Lumex CSS platform, which integrates the second-generation Arm Scalable Matrix Extension (SME2) new technology. Compared to the previous generation CPU, AI performance has been improved by up to five times, and energy efficiency has been optimized by three times.
At the recently held Arm Unlocked 2025 AI Technology Summit in Shenzhen, James McNiven, Vice President of Product Management at Arm’s Terminal Business Unit, further analyzed Arm’s new Lumex CSS platform, which integrates CPU clusters based on Armv9.3 architecture, processors equipped with second-generation Scalable Matrix Expansion (SME2) technology Mali G1-Ultra GPU、 Advanced system IP and mass production grade physical implementation solutions optimized for 3-nanometer process nodes.
It can be seen that the upgrades of Arm’s new platform are all aimed at accelerating the explosion of end-to-end AI. It can be foreseen that with Arm’s ongoing “platform first” strategy, Arm will continue to be a leader in key areas such as consumer electronics, automotive, and infrastructure in the wave of generative AI.

Arm launches new naming system Lumex, CPU uses’ clever tricks’ to significantly improve AI performance
This year, Arm released a new generation of products that no longer follow the previous naming convention, but instead adopt the new naming convention of Arm Lumex.
Lumex originates from Latin, meaning the light of the world, symbolizing leading people forward and promoting deeper interaction between light and people, similar to the concept of mobile terminals as a key and primary interactive device in our lives. ”James McNiven told Leifeng. com (official account: Leifeng. com), “We also widely heard feedback from ecological partners from the Chinese market, including the fact that the past naming methods were really complex, and the recognition of product iterations was not high. Therefore, we hope to make the brand system more clear and understandable through this renaming.”
James emphasized that the Arm Lumex CSS platform has once again achieved a double-digit increase in instructions per clock cycle (IPC) performance, marking Arm’s sixth consecutive year of double-digit growth, which means significant performance improvements can be achieved at the same power consumption.
Equally noteworthy as achieving IPC double-digit performance for six consecutive years is the direct embedding of a dedicated matrix acceleration unit, the second-generation scalable matrix extension (SME2), into the CPU. Before further analyzing SME2, let’s first introduce the brand new CPU.
After the new generation computing platform is renamed Lumex, the CPU no longer follows the previous Cortex naming convention, but adopts a more concise C1 naming system. The C1 CPU cluster is designed based on the Armv9.3 architecture, with four levels of Arm C1 Ultra, Arm C1 Premium, Arm C1 Pro, and Arm C1 Nano according to different customer and market demands.
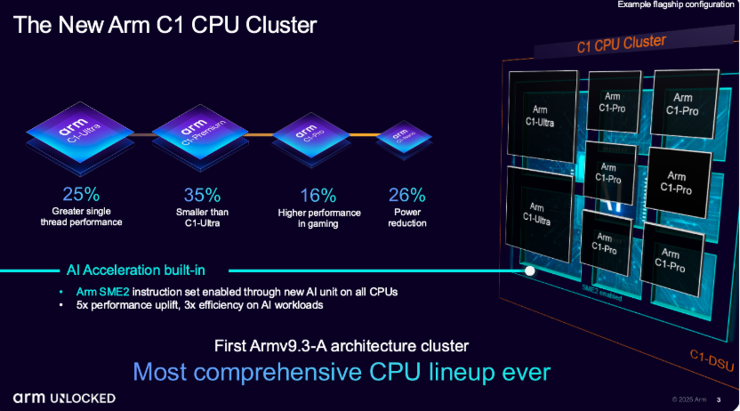
Arm C1 Ultra can provide the highest peak performance of flagship devices, achieving up to 25% improvement in single threaded performance; Arm C1 Premium is designed specifically for the secondary flagship market, with performance approaching C1 Ultra while reducing overall area by approximately 35%.
When any device adopts C1 Ultra or C1 Premium, it can be called a Lumex device. ”James said.
Arm C1 Pro is the new generation Cortex-A700 series, while Arm C1 Nano is the new generation Cortex-A500 series.
Although the performance levels of Arm C1 CPUs are different, they all deeply integrate SME2, which is designed specifically to accelerate matrix operations and related loads, making it very suitable for scenarios such as mobile devices that require extremely high power consumption and response speed.
Compared to SME1, SME2 has a performance improvement of 5 times and energy efficiency improvement of 3 times, demonstrating unique advantages in low latency and high real-time application scenarios.

Why is adding matrix acceleration to the CPU a “trick” to meet AI computing needs on the end side? James told Leifengwang, “Firstly, for latency sensitive scenarios, implementing matrix acceleration within the CPU can significantly improve the computational efficiency of applications, especially in fast AI inference scenarios where tasks no longer need to be passed back to the NPU, avoiding potential memory access delays. Secondly, almost all devices are equipped with CPUs, and Arm CPUs are widely used on the vast majority of mobile devices, which brings great convenience to developers. They do not need to adapt to different NPU architectures, nor do they need to redesign computing logic for different devices (as some terminals may not even have NPUs), and they can also avoid considering other factors such as security models. ”
Of course, adding matrix acceleration to the CPU significantly improves its AI performance, not to replace the role of GPU or NPU in handling AI loads, but to select the most suitable computing unit based on the type of load and provide users with the best AI experience.
Speech recognition is very suitable for acceleration using SME2, as this type of task requires extremely high response speed and relatively small data volume. Directly executing it on the CPU can not only significantly improve fluency.
At present, Arm has cooperated with mobile application partners including Alipay and Taobao to optimize the user experience based on the integration of SME2. Vivo and OPPO have also launched devices that support SME2. Arm has also collaborated with Tencent GiiNEX on gaming for SME2. Tencent’s preliminary test results show that the performance is improved by 2.5 times after enabling SME2. Google has also confirmed that it will support SME2 in future versions of the Android system.
However, adding matrix acceleration capability to the CPU is not a unique move of Arm. RISC-V is also using this approach to meet the needs of generative AI. What are the advantages of Arm?
James said, ‘Arm’s biggest advantage is that our CPU architecture has been applied to approximately 99% of smartphones worldwide.’. For developers, it is very easy to unify goals and deploy directly. ”
Double digit improvement in GPU performance, neural technology will be commercially available next year
Like the continuous double-digit improvement in CPU performance, Arm’s GPU has also achieved double-digit performance and energy efficiency improvements for four consecutive years. Corresponding to the naming system of C1 GPU, Arm GPU is named “Mali G1”.
The Mali G1 Ultra is a flagship GPU that can complete most inference tasks, including photos and videos, at lower power consumption. In various graphic benchmark tests, the Mali G1 Ultra achieved a 20% performance improvement compared to its predecessor and introduced a second-generation ray tracing unit. In the cross platform ray tracing performance test of Solar Bay Extreme, Arm’s latest ray tracing unit will achieve twice the performance improvement.

Arm’s ultimate goal of doubling ray tracing performance is to achieve more comprehensive and natural lighting effects in games – gradually transitioning from local lighting to full scene lighting. This will provide the gaming team with greater creative space, allowing them to integrate more ray tracing components in the same game, thereby achieving higher quality and more immersive lighting performance.
What is even more anticipated at the GPU level is Arm’s “neural technology” released in August this year, which will be used for terminal devices to be launched next year.

James introduced that neural technology is an important development direction for Arm in the future. This technology can help developers fully apply AI capabilities to graphics processing, whether it’s image enlargement, denoising, or new content generation, all of which will bring a more realistic and immersive visual experience. Currently, multiple developer communities and game studios are working together with Arm to advance this direction.
Of course, Arm’s open Arm ML extension for Vulkan makes it easier for developers to integrate AI as a native part of the graphics pipeline into mobile rendering.
The key to accelerating the explosion of end-to-end AI – developer friendliness
Arm’s new Lumex CSS platform has achieved double-digit performance improvements at both the CPU and GPU levels, as well as significant AI performance enhancements.
To fully unleash these capabilities, a developer friendly ecosystem is crucial, and Arm has invested heavily in it.
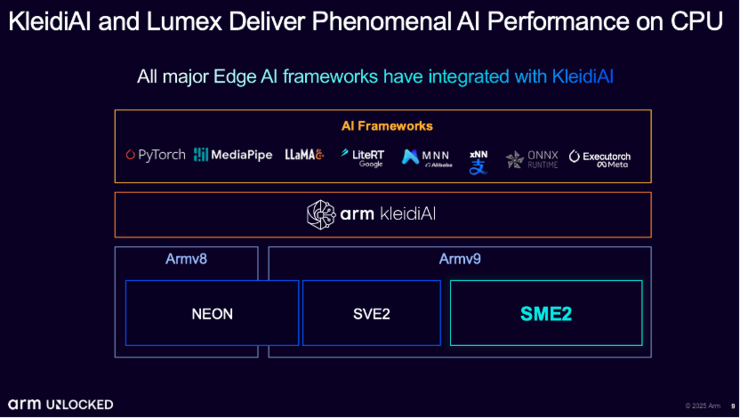
In order to enable developers to better unleash the potential of SME2, since last year, we have further expanded its functionality based on the KleidiAI software library. KleidiAI is designed to accelerate AI applications and has been deeply integrated with mainstream AI frameworks in the industry. This means that developers can have a consistent performance acceleration experience, whether it’s the old architecture or the latest architecture that supports SME2. ”James said.
Arm has launched the world’s first fully open neural graphics development kit for GPUs, aimed at integrating AI rendering into existing workflows, allowing developers to start development one year before hardware is available. This development kit was already supported by six major game studios when it was released in August this year, and a new game studio has recently completed integration testing.
In addition to better performance and a developer friendly ecosystem, the explosion of end-to-end AI also faces other technological challenges. James believes that in system level IT design, it is necessary to ensure efficient interconnection between the CPU and GPU, as well as between them and the storage system. Optimizing data interconnection to achieve more efficient data flow is one of the main challenges currently faced. Arm optimizes its interconnect architecture to further reduce latency during data transmission and achieve faster internal memory access.
Another prominent challenge is that AI applications emerge in new forms almost every few months or even weeks, involving different data types, operators, and instruction sets. Arm’s newly launched C1 CPU provides a highly flexible computing engine that can generate and execute almost any type of operator, processing various types of data.
In addition, like all AI participants, Arm also has to face various different scenarios. Arm’s strategy is to achieve differentiated needs in different segmented markets through microarchitecture. For example, the four tiered products of Arm C1 CPU not only provide customers with rich choices, but also make it easier for them to “customize” adaptation solutions for the target market.
In addition to the consumer electronics field, Arm also has the Arm Zena CSS computing platform for the automotive industry, the Arm Neoverse CSS computing platform for infrastructure, and the upcoming Arm Niva platform for the PC market.
Arm is accelerating the adoption of generative AI through a comprehensive computing platform that spans from the cloud to the edge and end to end.














暂无评论内容