
The culmination of open‑source AI. “Is this another DeepSeek‑style moment of brilliance? Open‑source software has once again outpaced closed‑source software.”
On November 6, 2025, Thomas Wolf, co‑founder of Hugging Face, summed up the discussions triggered by the release of the Kimi K2 Thinking model in a single post on X.
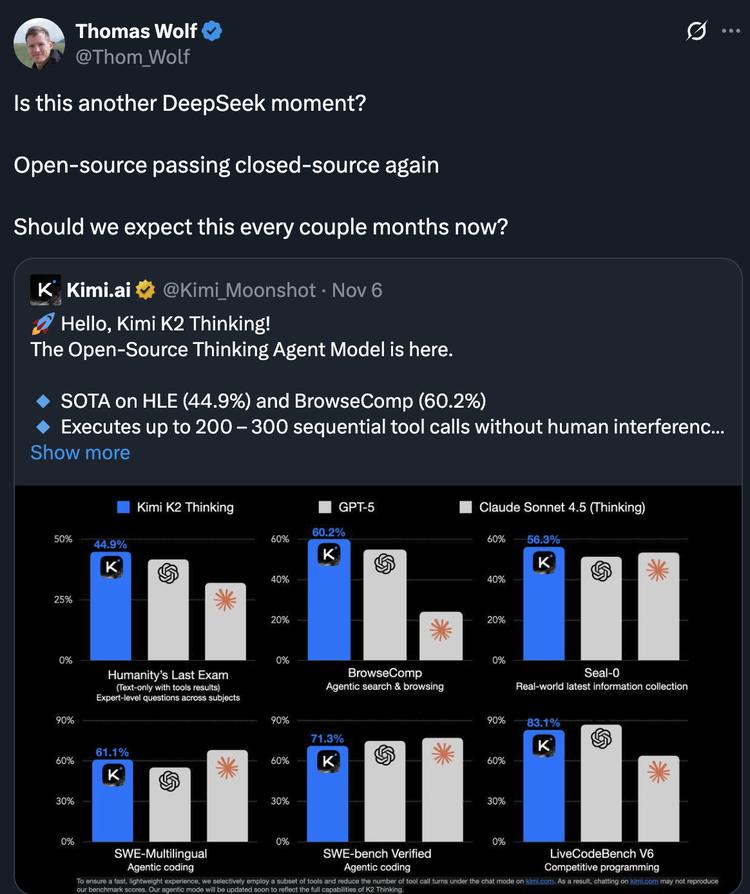
Kimi K2 Thinking has posted strong results on multiple benchmarks, matching or even surpassing closed‑source SOTA models. For example, on the text‑only subset of the HLE (Humanity’s Last Exam) benchmark, its tool‑augmented variant scored 44.9%, beating GPT‑5’s 41.7%.
Kimi K2 Thinking is trained based on the Kimi K2 model and focuses on improving agentic capabilities and reasoning. It is a trillion‑parameter hybrid Mixture‑of‑Experts (MoE) model with roughly 1 trillion total parameters; each forward pass activates about 32 billion parameters. It supports a 256k context window and uses native INT4 quantization. The design goal is to retain enormous model scale while controlling compute and training cost. According to CNBC citing informed sources, the model’s training cost was only $4.6 million. For comparison, DeepSeek disclosed V3’s training cost (rental price, main training phase) as $5.6 million and R1 as $294k. Those figures mainly account for GPU pretraining costs and exclude R&D, infrastructure, and other investments.
A core feature of Kimi K2 Thinking is its agent capability: the team claims it can execute 200–300 consecutive tool calls to solve complex problems. Closed‑source competitors like Grok‑4 commonly use RL to improve tool usage and long‑range planning, but seeing such an implementation in an open‑source model at this scale is novel. It shows the open‑source community is quickly catching up to agentic techniques, while also raising the bar for model‑hosting services.
Kimi K2 Thinking has not yet released a technical report; only a technical blog and user documentation are available, and they do not disclose training data, RL details, or full recipes. Shortly after the release, technical discussions about the model’s architecture began circulating. On X and Reddit, a side‑by‑side architectural comparison with DeepSeek started to spread, sparking debate about its technical lineage.
Against a backdrop of DeepSeek’s long‑anticipated R2, many assumed Kimi’s open‑source SOTA inference model — which appears to inherit parts of DeepSeek’s architecture — might effectively stand in for DeepSeek by delivering R2‑level results.
Architectural “inheritance” and engineering “magic”
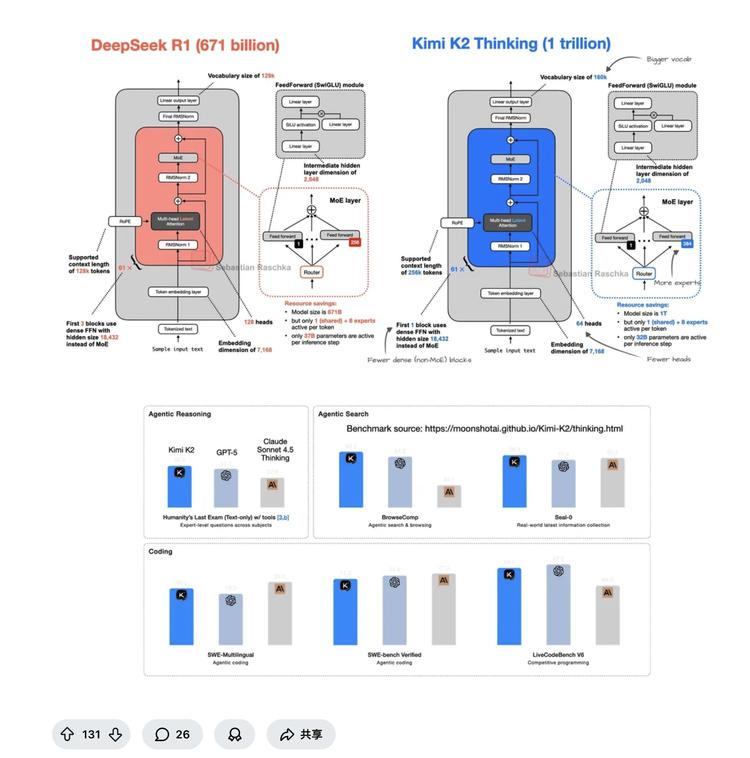
LLM research engineer Sebastian Raschka carried out a detailed analysis and pointed out specific similarities and differences between the two in a threads post:
– The number of experts per MoE layer is about 1.5× larger (384 vs. 256).
– A larger vocabulary (160k vs. 129k).
– K2 activates about 32B parameters per token (DeepSeek R1 activated ~37B).
– Fewer dense FFN blocks before the MoE layers.

“In short, Kimi K2 is essentially a slightly rescaled DeepSeek V3/R1. Its improvements mainly lie in data and training recipes,” Raschka wrote.
His analysis highlights a key fact: Kimi K2 Thinking’s “inheritance” of DeepSeek’s core architecture is evident, including MoE mechanisms and MLA (multi‑head latent attention) designs. On a validated base architecture, Kimi made targetted adjustments and optimizations to meet its goals — for example, reducing attention heads and activated parameters to lower inference cost, while increasing expert count and vocabulary to boost knowledge capacity and expressiveness. This approach — standing on the shoulders of giants — is a direct expression of open‑source spirit.
Beyond inheriting DeepSeek’s architecture, Kimi K2 Thinking’s achievements also rely heavily on adopting a wide range of open‑source ecosystem results: from FlashAttention for accelerating attention computation, to the MuonClip optimizer mentioned in K2’s blog for addressing training instability, and numerous data processing and post‑training methodologies that embody the community’s collective wisdom.
If architecture and open technology form the skeleton, what fleshes it out is Kimi’s own engineering execution, visible in three main areas:
1) Training stability: During 15.5 trillion tokens of pretraining, Kimi K2 Thinking reportedly experienced “zero loss spikes.” That means an extremely stable training run without costly rollbacks for crashes — a major engineering achievement for trillion‑parameter models.
2) Native quantized inference: Kimi K2 Thinking supports native INT4 inference, allegedly doubling inference speed with minimal performance loss and significantly reducing GPU memory requirements for deployment. This is critical for bringing very large models from labs into broad use.
3) Long‑range task execution: The model can stably perform 200–300 tool calls in sequence, which stresses both reasoning ability and system robustness. Sustaining hundreds of steps of interaction requires sophisticated engineering behind the scenes.
The Kimi team’s specific choices in integrating these open techniques, and their engineering team’s final execution, jointly underpin Kimi K2 Thinking’s current results. This technical route and success pattern remind many of the R1 release: inheriting DeepSeek’s MLA+MoE efficient architecture and a “task‑first verifiable” data/reward orientation, then stabilizing capabilities through engineering (e.g., MuonClip, long context, toolchains). The difference is that K2 Thinking’s openness and application delivery focus are stronger.
Trade‑offs beyond SOTA
A full assessment of Kimi K2 Thinking cannot stop at benchmark scores. One unavoidable point is how those benchmark scores are produced. Many of the SOTA numbers shown in Kimi K2 Thinking’s blog were obtained in a special “Heavy” mode. According to the official Hugging Face notes, this mode runs up to eight inferences in parallel and then reflectively aggregates all outputs to produce the final answer. This approach is common in academia and model competitions. At Grok 4’s July 9 release, xAI reported Grok 4 Heavy’s HLE score as 44.4% and its text‑only subset score as 50.7%.
The heavy mode brings issues: first, it consumes massive resources and is nearly impossible for ordinary users to reproduce via API or local deployment; second, it creates a gap between benchmark scores and single‑instance real‑world model capability. The standard mode that users can actually experience is not the same as the leaderboard’s “beast mode.”
The pursuit of efficiency also shows up in low‑level engineering choices that trade off performance for cost. For example, native INT4 quantization — while claimed to have minimal performance loss — compresses from FP16 to INT4 significantly. That quantization may hold up on standard benchmarks, but whether accumulated precision loss over very long or complex inference chains affects ultimate task success remains to be validated in broader real‑world use.
Similarly, reducing attention heads from 128 to 64 is a deliberate choice by the Kimi team to reduce memory bandwidth and compute. K2’s technical writeup also acknowledges that more attention heads typically yield better model quality. That implies Kimi K2 sacrifices some raw capability for greater inference efficiency.
Kimi K2 Thinking’s bet on agentic ability also brings other trade‑offs. Official benchmarks show K2 Thinking surpasses top models from OpenAI and Anthropic (GPT‑5 and Sonnet 4.5 Thinking) on “agent reasoning” and “agent search” metrics, but it has not yet topped “programming ability.”
In an era when frontier models increasingly ship multimodal by default, Kimi K2 Thinking remains a text‑only model. This gap is notable for tasks involving visual or spatial reasoning. For example, in generating an SVG image of “a pelican riding a bicycle,” a text‑only model may stumble due to lacking basic visual understanding of the physical world:
SVG generated by Kimi K2 Thinking
The release of Kimi K2 Thinking feels like another open‑source community carnival. It builds on outstanding open‑source work like DeepSeek, understands its current most important performance goals, refines details and training efficiency, and yields a new open‑source model that can outperform the strongest closed‑source models in today’s key directions. The model also feeds back ideas and inspiration to the open community, and serves as a piece of Kimi’s next, larger, more complete model — so perhaps the next DeepSeek moment is not far off, and it might not even have to come from DeepSeek itself.















暂无评论内容