

OmniVinci is NVIDIA’s all‑modal large model that can precisely parse video and audio, and is especially skilled at temporally aligning visual and auditory signals. At a scale of 9 billion parameters, it outperforms models of similar and even larger sizes, and its training data efficiency is six times that of rivals, greatly reducing costs. In scenarios such as video content understanding, speech transcription, and robot navigation, OmniVinci can provide efficient support and demonstrates outstanding multimodal application capabilities.
This year, the open‑source large model battlefield has been full of smoke and fire.
Groups from every direction are pouring in, trying to seize niches in the next era of AI. One trend that cannot be ignored is that Chinese large models are strongly dominating the “hall of fame” for open‑source foundational models.
From DeepSeek’s astonishing performance in code and mathematical reasoning to the Qwen (Tongyi Qianwen) family’s broad flowering in multimodal and general capabilities, they have already become unavoidable reference points for AI practitioners worldwide thanks to excellent performance and rapid iteration.
Just when everyone thought this open‑source foundational model wave would be driven mainly by top internet giants and star startups, a giant that “should have” been on the sidelines selling water has stepped in to add fuel.
Yes — NVIDIA, the biggest beneficiary of the AI wave, has not sat back from developing its own large models.
Now, NVIDIA’s large‑model matrix has welcomed a key piece.
Without further ado, the latest trump card from “Old Huang” is officially here: the most powerful 9B video‑audio omni‑modal large model, OmniVinci — now open‑sourced!
Paper: https://arxiv.org/abs/2510.15870
Code: https://github.com/NVlabs/OmniVinci
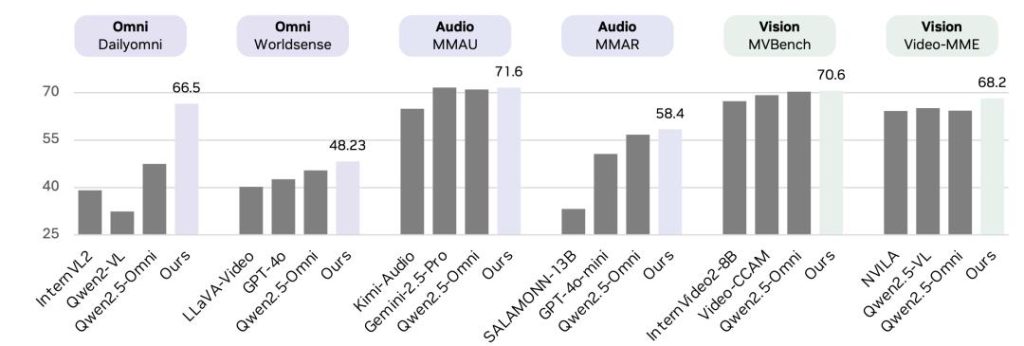
On multiple mainstream omni‑modal, audio‑understanding, and video‑understanding leaderboards, OmniVinci has delivered crushing performance against opponents:
If NVIDIA’s previous open‑source models were still niche plays in specific domains, OmniVinci’s release is a true full‑scale push.
NVIDIA defines OmniVinci as “Omni‑Modal” — a unified model capable of understanding video, audio, images, and text simultaneously.
At only 9 billion parameters, it delivers game‑changing performance across several key multimodal benchmarks.
According to NVIDIA’s paper, OmniVinci’s core advantages are sharp and striking:
– Cross‑level performance: On several authoritative omni‑modal understanding benchmarks (such as DailyOmni, MMAR, etc.), OmniVinci comprehensively outperforms competitors of the same tier (and even higher tiers), including Qwen2.5‑Omni.
– Incredible data efficiency: This is the most alarming point. OmniVinci reached current SOTA performance using only 0.2T (200 billion) tokens of training data. By comparison, major competitors typically use datasets of 1.2T tokens or more. That implies OmniVinci’s training efficiency is about six times that of its rivals.
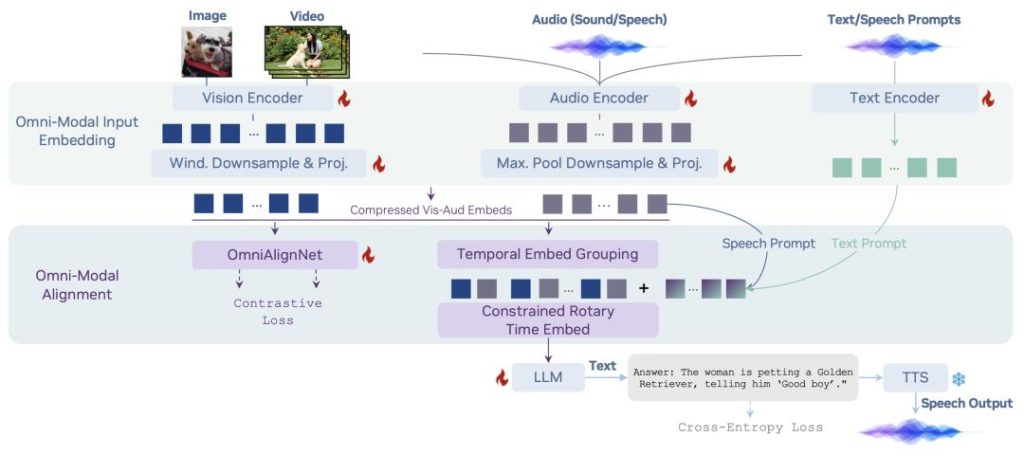
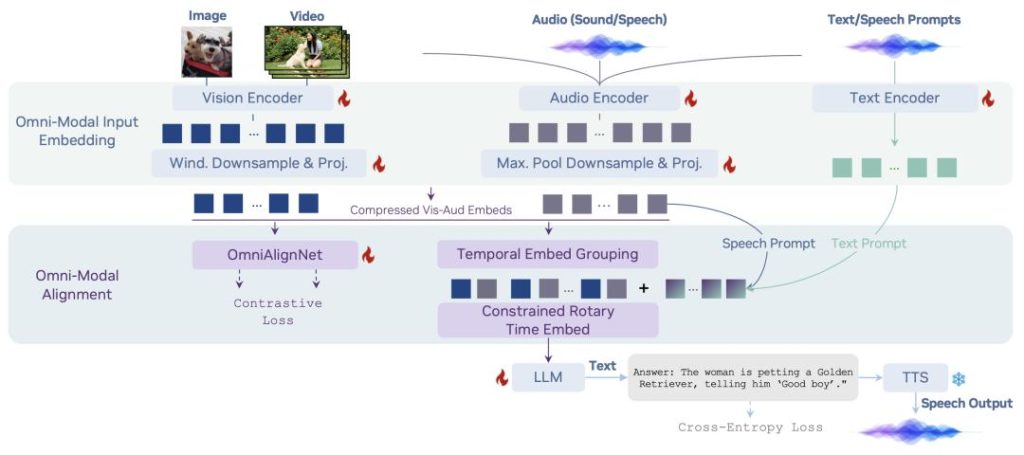
– Core technical innovations: Through an innovative architecture called OmniAlignNet, together with techniques like Temporal Embedding Grouping and Constrained Rotary Time Embedding, OmniVinci achieves high‑precision temporal alignment of visual and auditory signals. In short, it not only “sees” the video and “hears” the audio, but can accurately understand “what sound occurs in which frame.”
NVIDIA’s entry sends a clear message: the hardware king also wants to own the model definition layer.
Video + audio understanding: 1 + 1 > 2
Does adding audio actually make multimodal models stronger? Experiments give a clear answer: yes — and the improvement is significant.
The research team notes that sound introduces a new information dimension to visual tasks, greatly benefiting video understanding.
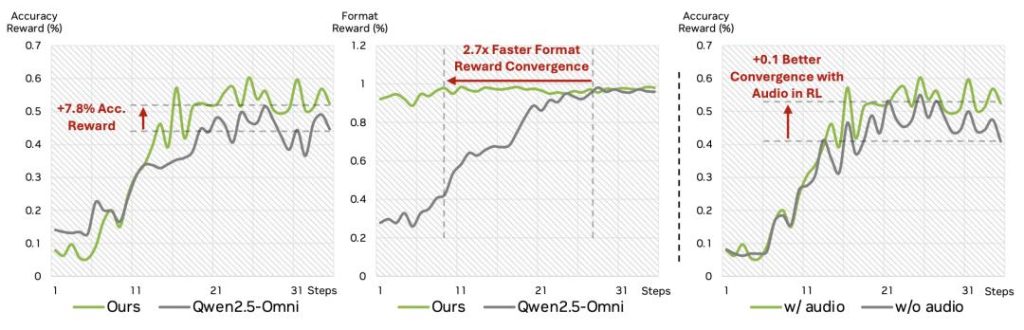
Specifically, performance improves in steps: from relying solely on vision, to implicit multimodal learning that combines audio, to explicit fusion driven by a full‑modal data engine. Especially when using explicit learning strategies, several metrics show breakthrough gains, with performance effectively “skyrocketing.”
Not only in SFT, but also adding the audio modality during post‑training further enhances GRPO’s effectiveness.

Full‑modal agents: broad application scenarios
A full‑modal model that handles both video and audio breaks the modality limits of traditional VLMs and can better understand video content, enabling broader application scenarios.

For example, it can summarize an interview with Jensen Huang; transcribe it into text; or be used to voice‑command robot navigation.

An ally, not an enemy, to the open‑source community
Over the past year, DeepSeek has repeatedly raised the ceiling on open‑source leaderboards with its strong prowess in code and math reasoning, becoming synonymous with the “top STEM performer.”
Qwen has built an extensive model matrix from the tiniest 0.6B to a 1T behemoth, making it one of the most complete and well‑balanced players in the ecosystem.
OmniVinci’s open‑sourcing feels like a “catfish” in the open‑source pond. With extreme efficiency and powerful performance it sets a new SOTA research benchmark, stirs the open‑source large‑model battlefield, and pushes fellow projects to deliver better models that help humanity move toward AGI.
For the “shovel‑sellers” like NVIDIA — the more people use open‑source models, the more GPUs they sell — open‑sourcing models is clearly beneficial. For this reason, NVIDIA is a steadfast ally of open‑source model teams, not an adversary.
community celebration, an accelerating tide, moving toward AGI together
Since NVIDIA OmniVinci’s release, it has fallen into the already churning open‑source sea like a giant rock and has already surpassed ten thousand downloads on Hugging Face.
Tech bloggers overseas have rushed to publish videos and articles sharing the related technology.
OmniVinci is both a natural extension of NVIDIA’s “hardware‑software” ecosystem and a powerful booster for the entire AI open‑source ecosystem.
Thus the open‑source landscape becomes clearer.
On one side are Chinese open‑source forces represented by DeepSeek and Qwen, which have built a thriving developer base through rapid iteration and openness.
On the other side is NVIDIA, holding compute dominance, stepping in directly with “technical benchmarks” and “ecosystem incubation” to accelerate the whole process.
The tide is accelerating and no one can stay on the sidelines. For every AI practitioner, a stronger, faster, and more competitive AI era is just beginning.
References:
https://arxiv.org/abs/2510.15870















暂无评论内容