
A Historic Breakthrough for Open-Source Models
As U.S. AI giant OpenAI faces growing scrutiny over its massive spending commitments, Chinese open-source AI providers are accelerating the competition — with one even outperforming OpenAI’s flagship paid proprietary model GPT-5 in key third-party performance benchmarks, using a completely free model.
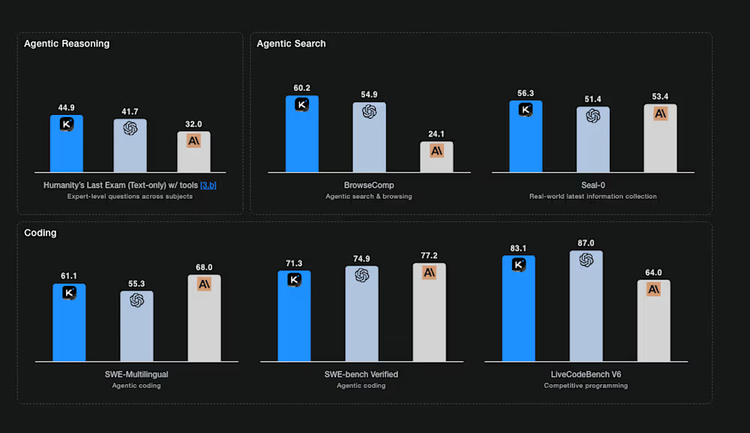
Moonshot AI’s newly launched Kimi K2 Thinking model has surpassed all proprietary and open-source competitors in benchmarks for reasoning, programming, and agent tool usage, claiming the top spot.
Despite being fully open-source, the model currently outperforms OpenAI’s GPT-5, Anthropic’s Claude Sonnet 4.5 (Thinking mode), and xAI’s Grok-4 in multiple standard evaluations — marking a historic turning point for the competitiveness of open AI systems.
Developers can access the model via platform.moonshot.ai and kimi.com; weights and code are hosted on Hugging Face. The open-source release includes APIs for chat, reasoning, and multi-tool workflows.
Users can try Kimi K2 Thinking directly through its ChatGPT-like website and Hugging Face Spaces.
—
Modified Open-Source License: Business-Friendly
Moonshot AI officially released Kimi K2 Thinking on Hugging Face under a modified MIT license.
The license grants full commercial and derivative rights — meaning individual researchers and developers working on behalf of enterprise clients can access and use it in commercial applications for free — with one additional restriction:
“If the monthly active users of the Software or any derivative work exceed 100 million, or the monthly revenue exceeds 20 million US dollars, the deployer must prominently display the ‘Kimi K2’ logo on the product’s user interface.”
For most research and enterprise applications, this clause functions as a lightweight attribution requirement while preserving the flexibility of the standard MIT license.
This makes K2 Thinking one of the most permissively licensed cutting-edge models available today.
—
The New Benchmark Leader
Kimi K2 Thinking is a trillion-parameter Mixture of Experts (MoE) model, activating 32 billion parameters per inference.
It combines long-range reasoning with structured tool usage, capable of executing 200-300 consecutive tool calls without human intervention.
Performance Highlights
According to test results released by Moonshot AI, K2 Thinking achieved:
– 44.9% on Humanity’s Last Exam (HLE), reaching industry-leading levels
– 60.2% on BrowseComp (agent web search and reasoning test)
– 71.3% on SWE-Bench Verified and 83.1% on LiveCodeBench v6 (key programming evaluations)
– 56.3% on Seal-0 (real-world information retrieval benchmark)
In these tasks, K2 Thinking consistently outperformed GPT-5’s corresponding scores and surpassed MiniMax-M2 — the previous open-source leader released by MiniMax AI just weeks earlier.
—
Open-Source Model Surpasses Proprietary Systems
GPT-5 and Claude Sonnet 4.5 Thinking remain leading proprietary “thinking” models.
However, in the same benchmark suite, K2 Thinking’s agent reasoning scores exceeded both: for example, on BrowseComp, the open-source model’s 60.2% significantly outperformed GPT-5’s 54.9% and Claude 4.5’s 24.1%.
K2 Thinking also narrowly edged out GPT-5 on GPQA Diamond (85.7% vs. 84.5%) and matched it on mathematical reasoning tasks like AIME 2025 and HMMT 2025.
Only under certain heavyweight mode configurations — where GPT-5 aggregates multiple reasoning trajectories — can proprietary models regain parity.
Moonshot AI’s full open-source weight release achieving scores on par with or exceeding GPT-5 marks a turning point. The gap between closed cutting-edge systems and publicly available models has effectively disappeared in high-end reasoning and programming.
—
Surpassing MiniMax-M2: The Former Open-Source Champion
Just a week and a half ago, when VentureBeat reported on MiniMax-M2, it was hailed as the “new king of open-source LLMs,” achieving top scores among open-weight systems:
– τ²-Bench: 77.2
– BrowseComp: 44.0
– FinSearchComp-global: 65.5
– SWE-Bench Verified: 69.4
These results brought MiniMax-M2 close to GPT-5-level agent capabilities at a fraction of the computational cost. Now, Kimi K2 Thinking has surpassed them by a significant margin.
Its BrowseComp result of 60.2% outperforms M2’s 44.0%, and its SWE-Bench Verified score of 71.3% exceeds M2’s 69.4%. Even on financial reasoning tasks like FinSearchComp-T3 (47.4%), K2 Thinking performs comparably while maintaining exceptional general reasoning capabilities.
—
Technological Innovations
From a technical perspective, both models adopt sparse Mixture of Experts architectures to improve computational efficiency, but Moonshot AI’s network activates more experts and deploys advanced Quantization-Aware Training (INT4 QAT).
This design doubles inference speed without reducing accuracy — crucial for supporting long “thinking token” conversations with a context window of up to 256k tokens.
Agent Reasoning and Tool Usage
K2 Thinking’s core strength lies in its explicit reasoning trajectories. The model outputs an auxiliary field `reasoning_content`, revealing intermediate logic before each final response. This transparency maintains coherence in long multi-turn tasks and multi-step tool calls.
Moonshot AI’s reference implementation demonstrates how the model can autonomously execute a “daily news report” workflow: calling date and web search tools, analyzing retrieved content, and generating structured output — while preserving internal reasoning states.
This end-to-end autonomy enables the model to plan, search, execute, and synthesize evidence across hundreds of steps, reflecting the emerging category of “agent AI” systems that operate with minimal supervision.
—
Efficiency and Access Costs
Despite its trillion-parameter scale, K2 Thinking maintains moderate running costs. Moonshot AI lists the usage prices as:
– $0.15 per million tokens (cache hit)
– $0.60 per million tokens (cache miss)
– $2.50 per million tokens (output)
These prices even undercut MiniMax-M2’s $0.30 input / $1.20 output pricing — and are an order of magnitude lower than GPT-5’s $1.25 input / $10 output.
—
Context: Accelerating Open-Weight Development
The rapid successive releases of M2 and K2 Thinking demonstrate how quickly open-source research is catching up to cutting-edge systems. MiniMax-M2 proved that open-source models could approach GPT-5-level agent capabilities at a fraction of the computational cost. Moonshot AI has now pushed this frontier further, shifting open weights from parity to outright leadership.
Both models rely on sparse activation for efficiency, but K2 Thinking’s higher activation count (32 billion vs. 10 billion active parameters) delivers stronger reasoning fidelity across domains. Its test-time scaling — expanding “thinking tokens” and tool call rounds — provides measurable performance gains without retraining, a feature not yet observed in MiniMax-M2.
—
Technical Outlook
Moonshot AI reports that K2 Thinking supports native INT4 inference and a 256k token context window with minimal performance degradation. Its architecture integrates quantization, parallel trajectory aggregation (“heavyweight mode”), and MoE routing optimized for reasoning tasks.
In practice, these optimizations allow K2 Thinking to sustain complex planning loops — code compile-test-fix, search-analyze-summarize — across hundreds of tool calls. This capability underpins its exceptional performance on BrowseComp and SWE-Bench, where reasoning continuity is critical.
—
Transformative Impact on the AI Ecosystem
The convergence of open and closed models at the high end marks a structural shift in the AI landscape. Enterprises that once relied entirely on proprietary APIs can now deploy open-source alternatives matching GPT-5-level reasoning, while retaining full control over weights, data, and compliance.
Moonshot AI’s open release strategy follows precedents set by DeepSeek R1, Qwen3, GLM-4.6, and MiniMax-M2 — but extends it to full agent reasoning.
For academic and enterprise developers, K2 Thinking offers transparency and interoperability — the ability to inspect reasoning trajectories and fine-tune performance for domain-specific agents.
—
Strategic Timing: Challenging AI Investment Models
K2 Thinking’s arrival signals that Moonshot AI — a young startup founded in 2023 with investment from some of China’s largest app and tech companies — is ready to compete in the intensifying race, just as the financial sustainability of the AI industry’s biggest players faces growing scrutiny.
Just one day earlier, OpenAI CFO Sarah Friar stated at the WSJ Tech Live event that the U.S. government might ultimately need to “backstop” the company’s over $1.4 trillion in computing and data center commitments — a comment widely interpreted as a call for taxpayer-supported loan guarantees, sparking controversy.
While Friar later clarified that OpenAI is not seeking direct federal support, the incident reignited debates about the scale and concentration of AI capital expenditures.
As OpenAI, Microsoft, Meta, and Google compete to secure long-term chip supplies, critics warn of an unsustainable investment bubble and “AI arms race” driven more by strategic fear than commercial returns — one that could “burst” and drag down the global economy if hesitation or market uncertainty emerges, given that too many deals and valuations now rely on expectations of continued massive AI investment and outsized returns.
Against this backdrop, open-weight releases from Moonshot AI and MiniMax are putting additional pressure on U.S. proprietary AI companies and their backers to justify the scale of their investments and path to profitability.
—
A Fundamental Challenge to Business Logic
If enterprise clients can get performance from free open-source Chinese AI models that equals or exceeds paid proprietary AI solutions (such as OpenAI’s GPT-5, Anthropic’s Claude Sonnet 4.5, or Google’s Gemini 2.5 Pro) — why would they continue paying for access to proprietary models?
Silicon Valley benchmarks like Airbnb have already drawn attention for acknowledging heavy use of Chinese open-source alternatives like Alibaba’s Qwen instead of OpenAI’s proprietary offerings.
For investors and enterprises, these developments indicate that high-end AI capabilities are no longer synonymous with high-end capital expenditure. The most advanced reasoning systems may not come from companies building ultra-large-scale data centers, but from research teams optimizing architectures and quantization for efficiency.
In this sense, K2 Thinking’s benchmark dominance is not just a technical milestone — it’s a strategic one, arriving at a time when the biggest question in the AI market has shifted from “how powerful can models get” to “who can afford to sustain them.”
—
Forward-Looking Significance for Enterprises
Within weeks of MiniMax-M2’s rise, Kimi K2 Thinking has surpassed it — as well as GPT-5 and Claude 4.5 — in nearly every reasoning and agent benchmark.
The model proves that open-weight systems can now match or exceed proprietary cutting-edge models in both capability and efficiency.
For the AI research community, K2 Thinking is more than just another open-source model: it’s evidence that the frontier has become collaborative.
The best-performing reasoning model available today is not a closed commercial product, but an open-source system accessible to anyone.













暂无评论内容