

“AI unicorns are back in the spotlight.” An AI industry insider sighed, referring to the recent performance of domestic large models.
The latest example is Moon’s Dark Side’s trillion-parameter reasoning model Kimi K2 Thinking, which reportedly basically surpasses leading closed-source models such as GPT-5 and has topped global open-source model rankings.
Notably, this model was trained at a relatively low cost. Sohu Tech learned that the training cost for Kimi K2 Thinking was about $4.6 million (roughly RMB 32 million).
That breaks DeepSeek’s record. DeepSeek previously disclosed that its V3 model cost only $5.6 million to train, which once shocked the global AI community; now Kimi K2 Thinking has cut that by another million dollars.
“This is China’s closest moment to OpenAI,” “another DeepSeek moment,” many commented. Besides Moon’s Dark Side, Zhipu and MiniMax’s models have also recently gained traction overseas.
DeepSeek-R2 hasn’t arrived yet and seems no longer the center of attention; once-dominant domestic AI unicorns are returning to the global stage as they try to reclaim technological discourse.
“Another DeepSeek moment”
Trillion parameters, open-source top ranking, catching up to GPT-5… these are the attention points around Moon’s Dark Side’s new reasoning model Kimi K2 Thinking.
Official evaluations show the model exceeds or approaches GPT-5 and Claude Sonnet 4.5 across reasoning, coding, and other capabilities, and achieved SOTA results on several benchmarks including the “Humanity’s Last Exam.”

“This is a historic breakthrough for open-source models.” In Artificial Analysis (AA)’s latest global comprehensive model evaluation, Kimi K2 Thinking jumped to second place worldwide, only one point behind GPT-5.
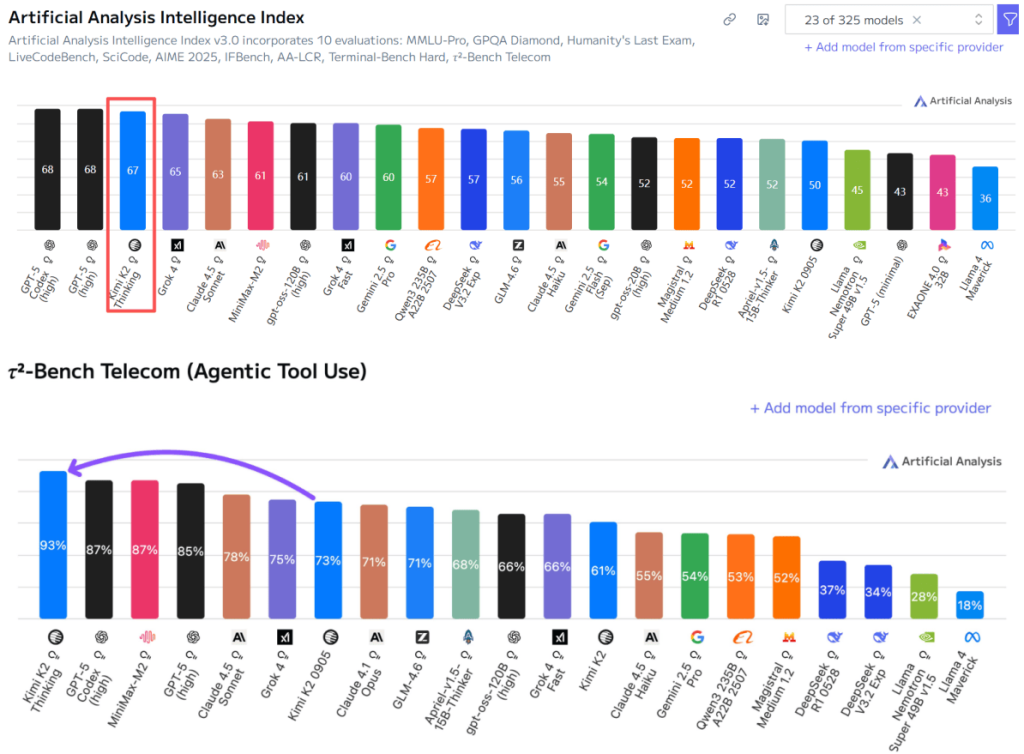
In AA’s agent benchmark τ2-Bench, on telecom tasks Kimi K2 Thinking rose to first place, outperforming GPT-5, Claude Sonnet 4.5, Grok4 and other leading models.
Moon’s Dark Side’s introductory post about the model on overseas social platforms garnered more than 4.4 million views in a few days, again shifting overseas perceptions of Chinese large models; some commentators called it another “DeepSeek moment.”
This model was trained at a lower cost than DeepSeek. Sohu Tech learned from insiders that Kimi K2 Thinking’s training cost was about $4.6 million—far below investments by OpenAI and others, and breaking DeepSeek-V3’s about $5.6 million training cost record.
“Compared with top U.S. models, this cost is very low. Most Chinese models operate on similar budgets; many companies don’t have that many chips available, so it comes down to who trains better,” an AI practitioner said.
Why Kimi K2 Thinking could be trained so cheaply has not been detailed in a public technical paper; the industry believes it stems from optimizations in algorithms, architecture, and post-training, with a key point being adoption of native INT4 quantization.
INT4 refers to a quantization technique in large language models that reduces the numerical precision of model parameters to lower storage and compute needs while trying to preserve performance.
Moon’s Dark Side researcher Liu Shaowei wrote that during K2-Thinking development they found that as generated sequence length grows, achieving low-latency inference requires an INT4 QAT (quantization-aware training) scheme that incurs smaller quantization loss—this also significantly improved the efficiency of post-training reinforcement learning.
Asked why not adopt “more advanced” formats, Liu said it was to better support non-Blackwell-architecture hardware. “In the large-model era, quantization is a concept that can sit alongside SOTA and Frontier, and can even accelerate a model’s path to the Frontier,” he wrote.
However, many tests show Kimi K2 Thinking is rather “talkative.” In AA’s intelligence index evaluation it consumed a total of 140 million tokens—2.5 times DeepSeek V3.2’s usage and twice GPT-5’s—raising inference cost and slowing speed to some extent.
“Now, the world’s smartest model is open-source and it comes from China. If the U.S. continues to work behind closed doors, Chinese open-source models could completely win,” one comment read.
Jensen Huang (Huang Renxun), the world’s richest Chinese person, recently noted that China’s AI tech is excellent and that many of the world’s most popular open-source AI models come from China and are developing rapidly.
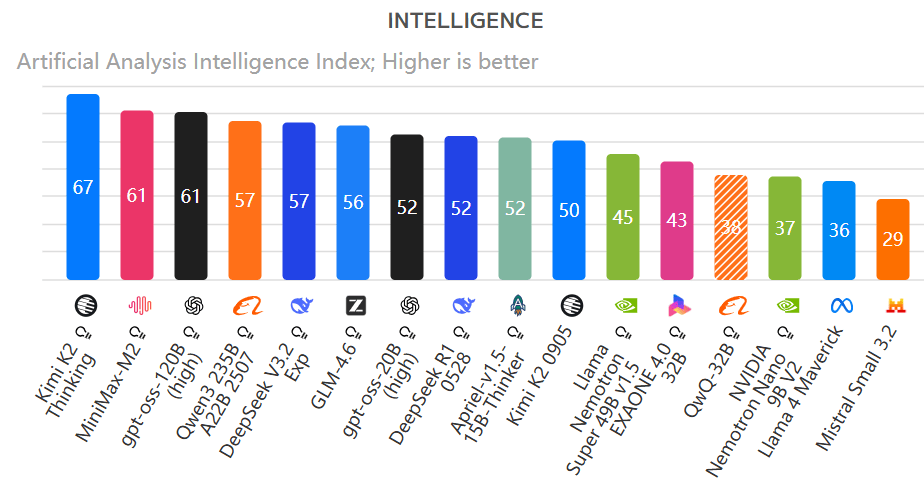
That’s true: Chinese open-source models currently lead both in capability and quantity. This year’s open-source top spot has rotated among Chinese models.
In AA’s latest global open-source model list, six of the top ten models are from China, with Kimi K2 Thinking ranking first, replacing MiniMax-M2, which held the top spot half a month earlier, and earlier leaders from Alibaba and DeepSeek.
Recently, the U.S. tech scene led by OpenAI has tied compute infrastructure to huge investments worth trillions, leveraging its advantages to the fullest—an approach hard to replicate in China.
For most Chinese model firms, breakthroughs are needed at the algorithm, architecture, and engineering levels, as DeepSeek and Kimi have done. Small innovations accumulate and can eventually yield surprising results.
A clear signal is that Chinese AI unicorns are returning to the technology race and back into the spotlight. DeepSeek has already fallen outside AA’s top ten; perhaps only R2 could stage a comeback.
Chinese models find users in Silicon Valley
Behind Kimi’s breakout is growing overseas interest in Chinese large models—Silicon Valley is beginning to shift from expensive closed-source models toward cheaper Chinese open-source alternatives.
Silicon Valley investor Chamath Palihapitiya recently admitted he has moved a lot of workloads to Kimi K2.
U.S. cloud company Vercel launched an API service for the model; AI programming firms Cursor and Windsurf, Baidu ex-exec Jing Kun’s U.S. startup Genspark, and AI search company Perplexity have all integrated it.
MiniMax’s inference model M2 reached top-three global call volume on the OpenRouter model router within days of release, became the most downloaded model on HuggingFace for a time, and has at least 20 platforms offering API access.
There have also been cases of U.S. companies “repackaging” Chinese models. Cursor’s Composer code model was found to be a wrapped version of China’s GLM-4.6, according to developers.
GLM-4.6, released by Zhipu at the end of September, claimed top domestic code capabilities aligned with Claude Sonnet 4 and ranked first among open-source code models on LMArena.
Two other coding AI firms, Cognition and Windsurf, were also found to be wrapping GLM-4.6; after being exposed, Windsurf responded to community pressure by making GLM-4.6 available, saying it “provides superior code generation and programming task performance.”
Many AI practitioners were excited. “Before, Chinese models were the ones being wrapped by overseas projects; now our models are being wrapped—China’s models are finally holding their heads high.”
In short, Chinese large models’ overseas expansion has entered a new stage: from initial discussion to product-level breakout, and now multiple domestic foundational models being adopted by overseas companies. The “Made in China” label in large models is gaining credibility.
Importantly, these models chose to be open-source, allowing global developers and companies to use them freely, and Chinese models are increasingly building technical influence through open-source.
Of course, open-source requires real capability; the reason Silicon Valley is choosing Chinese models is their extreme cost-effectiveness.
Vercel CEO Guillermo Rauch said that in internal, real-world agent benchmarks Kimi K2 outperformed GPT-5 and Claude Sonnet 4.5 in runtime speed and accuracy, with accuracy reportedly 50% higher.
Chamath said Kimi-K2 is powerful and much cheaper than OpenAI and Anthropic.
Data show Kimi-K2, Kimi K2 Thinking and Zhipu GLM-4.6 API output pricing is about 20% of GPT-5’s price, less than 15% of Claude Sonnet 4.5’s; MiniMax-M2’s price is only about 8% of Claude Sonnet 4.5’s.
“This is an important moment—Chinese open-source models have enough capability to support Western product development. Global AI is moving into a new multipolar competitive landscape,” one commentator said. Some overseas netizens even joked: maybe it’s time to learn some Chinese?
Funding and listings: AI unicorns seek paths forward
With technological catch-up and overseas traction, China’s AI unicorns are trying to stay at the table—this gives them more confidence as they pursue IPOs and new fundraising rounds.
Moon’s Dark Side was reported to be seeking a new funding round and rumors circulated that a16z was considering investing. Sources said the round would be about $600 million, with a pre-money valuation of $3.8 billion; lead investors pointed to IDG, with Tencent, Wuyuan Capital and Today Capital among existing investors set to follow.
If the funding goes through, Moon’s Dark Side could become another AI unicorn valued at over RMB 30 billion, joining Zhipu and MiniMax.
Sohu Tech asked Moon’s Dark Side and mentioned investors for confirmation; they did not respond. An AI-focused investor noted that such a large financing usually takes a long decision process, and American funds are unlikely to invest in the current environment.
Regarding the valuation, the investor said that in a cooled domestic model funding market, this valuation is not low, but still far below American model unicorns—Moon’s Dark Side’s valuation is under 1% of OpenAI and Anthropic’s. “It’s still too hard for domestic large models to make money.”
Two years ago, Moon’s Dark Side was a hot market star—last year it raised over $1.3 billion across two rounds, once valuing the company at $3.3 billion, and Kimi became the most trafficked domestic AI-native app.
However, after a dispute between co-founders Zhang Yutong and Zhu Xiaohu and the impact of DeepSeek’s challenge, Moon’s Dark Side faced doubts; the company paused product growth, shifted focus to tech, and moved from closed-source to open-source.
Since this year, Kimi’s user growth stalled or declined. According to QuestMobile, in September this year Kimi’s monthly active users were below ten million—down by over 11 million from December last year—dropping from second to fifth among domestic AI-native apps.
Commercially, Moon’s Dark Side continues to bet on the consumer market, having launched OK Computer overseas and introduced subscriptions. In a domestic market where many similar products are free and competition is fierce, this could be a long, grueling battle.
In that context, this fundraising round is especially important for Moon’s Dark Side—especially as peers like Zhipu and MiniMax pursue IPOs, the company needs more capital to face future uncertainties.
Earlier this year MiniMax closed nearly $300 million in a new round, with a post-money valuation above $4 billion and Shanghai state capital participating. The company reportedly plans to list in Hong Kong; insiders confirmed IPO ambitions.
MiniMax’s overseas consumer apps—companion app Talkie and video-generation Conch AI—are its main revenue sources; it recently launched paid features for coding and agent products, doubling down on consumers.
Zhipu, focused on government and enterprise markets, completed multiple state-backed financing rounds and has begun IPO preparations; it may submit a STAR Market (Sci-Tech Innovation Board) prospectus this year, potentially becoming the first listed large-model company. Zhipu has also faced layoffs, reflecting commercialization and listing challenges.
Visibly, among the “four AI tigers,” Jieyue Xingchen seems to have fallen behind. AI unicorns still face survival pressure in the mix of technological ideals and market realities, and the final competitive landscape is far from decided.















暂无评论内容