The rules of the AI inference game are quietly changing. A new report reveals a pivotal shift: what now determines winners and losers is no longer raw chip performance or GPU count, but rather “how much intelligence you get per dollar.”
AI inference is no longer just about hard compute metrics!
According to a recent report from Signal65, NVIDIA’s GB200 NVL72 delivers 28x the throughput of AMD’s MI355X (note: likely a typo in original text—should be MI355X, not MI350X).
Moreover, in high-interactivity scenarios with DeepSeek-R1, the cost per token can be as low as 1/15th that of competing platforms.
While the GB200’s hourly price is roughly twice as high, that hardly matters. Thanks to its rack-scale NVLink interconnect and advanced software orchestration, the entire cost structure has been transformed.
Top investor Ben Pouladian put it succinctly:
“The key today isn’t compute or GPU count—it’s how much intelligent output you get per dollar.”
For now, NVIDIA remains king. Competitors simply cannot match this level of interactivity—that’s the moat.
And critically, this analysis doesn’t even include the inference capabilities NVIDIA will gain from its $20 billion acquisition of Groq.
This brings us back to Jensen Huang’s timeless wisdom:
“The more you buy, the more you save!”
The New Focus in AI Inference: Intelligence per Dollar
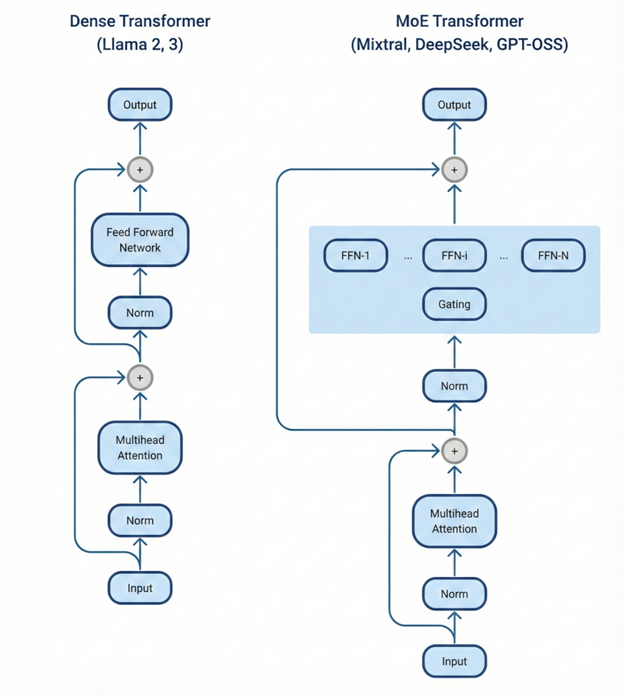
This in-depth report explores the fundamental shift from dense models to Mixture-of-Experts (MoE) architectures in AI inference.
Traditional dense models activate all parameters for every single token generated.
This means: the larger the model, the slower and more expensive it becomes to run—accompanied by soaring memory demands.
MoE architectures, by contrast, were designed to unlock higher intelligence efficiently—activating only the most relevant “experts” for each token.
A quick glance at the Artificial Analysis leaderboard confirms the trend: all top 10 open-weight LLMs are MoE reasoning models.
These models apply extra compute during inference to boost accuracy:
Instead of immediately outputting an answer, they first generate intermediate reasoning tokens—essentially “thinking through” the problem before responding.
These reasoning tokens often vastly outnumber the final visible response—and may never be shown to the user at all. Thus, the ability to generate tokens quickly and cheaply becomes critical for scalable inference deployments.
What’s the main constraint of MoE?
A core bottleneck is communication overhead.
When experts are distributed across multiple GPUs, any delay in inter-GPU communication forces GPUs to sit idle—waiting for data.
This “idle time” represents wasted, inefficient compute that directly inflates service providers’ bottom-line costs.
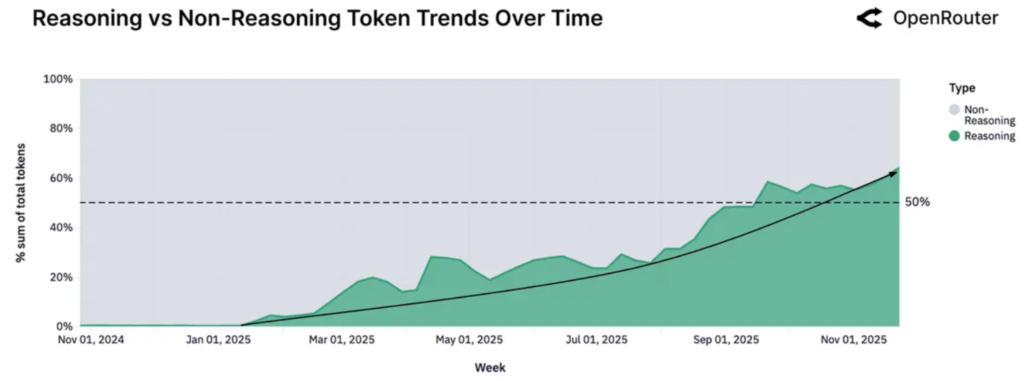
According to a recent OpenRouter report, over 50% of all tokens are now routed through reasoning models.
Evaluating AI Infrastructure Economics
When assessing AI infrastructure economics, discussions typically center on three dimensions:
Performance (throughput and interactivity)
Energy efficiency (tokens per watt)
Total Cost of Ownership (TCO) — often expressed as cost per million tokens
Signal65’s analysis uses publicly available benchmark data (from InferenceMAX) to estimate relative token economics—avoiding vendor claims.
They compared:
NVIDIA B200
NVIDIA GB200 NVL72
AMD MI355X
Key finding: While B200 outperforms MI355X on dense and small MoE models, when scaling to frontier-class models like DeepSeek-R1 beyond a single node, all 8-GPU systems (NVIDIA and AMD alike) hit a “scaling ceiling” due to communication bottlenecks.
But the NVIDIA GB200 NVL72 breaks through this limit.
Public DeepSeek-R1 benchmarks show:
Up to 28x higher performance than MI355X
Cost per token as low as 1/15th of alternatives in high-interactivity workloads
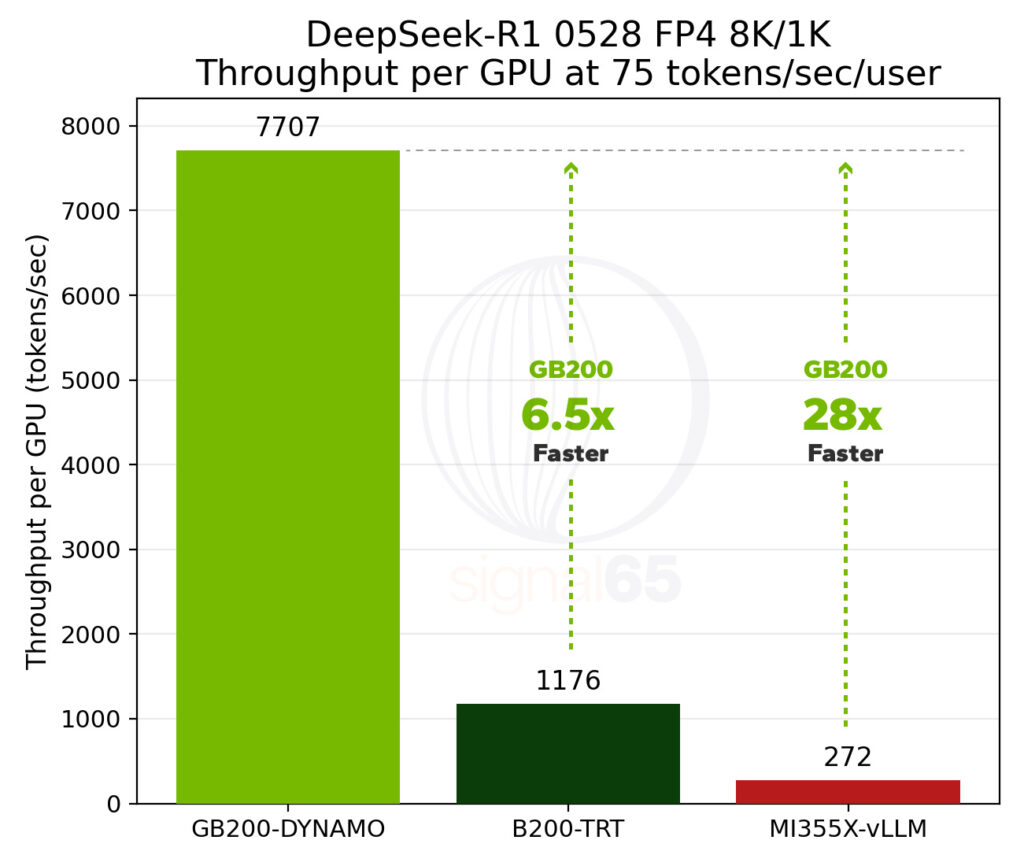
Although the GB200 NVL72 carries nearly 2x the per-GPU hourly price, its rack-scale capabilities—from NVLink fabric to software orchestration across 72 GPUs—deliver vastly superior unit economics.
Value is shifting from raw FLOPs to total intelligence per dollar.
As MoE models and reasoning workloads grow in complexity and scale, the industry can no longer rely on chip-level performance alone. End-to-end platform design that maximizes system-wide performance has become the primary lever for cost-effective, responsive AI.
Dense Model Inference: NVIDIA Leads
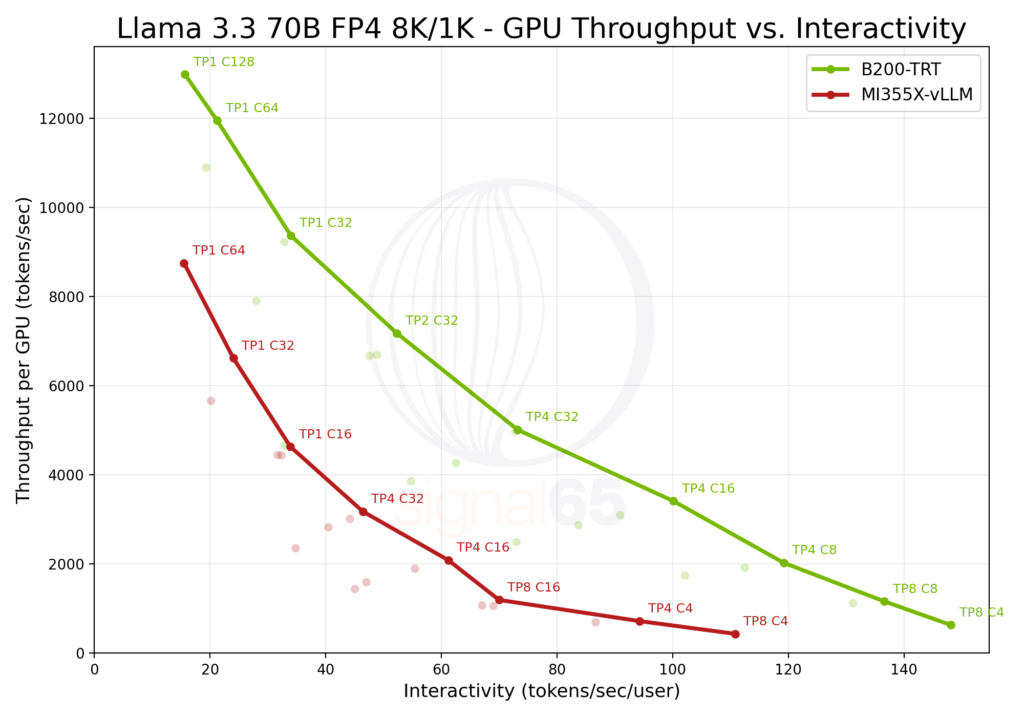
Signal65 used Llama 3.3 70B as the dense model baseline—a modern, widely deployed LLM.
Results show consistent NVIDIA advantage:
At baseline interactivity: 1.8x higher performance than MI355X
At 110 tokens/sec/user: over 6x higher throughput
While AMD offers competitive performance-per-dollar in dense models, this advantage does not extend to modern MoE and reasoning-heavy stacks.
MoE Inference: NVIDIA Pulls Ahead
Moderate Reasoning MoE: gpt-oss-120B
OpenAI’s gpt-oss-120B (117B params, 128 experts, 4 active per token) serves as a bridge between dense and frontier MoE models.
Late October 2025: B200 was 1.4x faster at 100 tokens/sec/user, but 3.5x faster at 250 tokens/sec/user
Early December 2025 (after software updates):
B200 peak throughput: ~14,000 tokens/sec/GPU (up from ~7,000)
MI355X: ~8,500 tokens/sec/GPU (up from ~6,000)
At 100 tokens/sec/user: B200 now 3x faster
At 250 tokens/sec/user: 6.6x faster
Takeaway: MoE differentials widen significantly under high interactivity—unlike dense models.
Frontier Reasoning MoE: DeepSeek-R1
DeepSeek-R1 (671B total params, 37B activated) stresses infrastructure with:
MoE routing
Massive KV cache pressure
Long reasoning chains
Here, single-node 8-GPU systems hit a wall. Expert parallelism across many nodes becomes essential—but introduces severe communication bottlenecks.
Enter NVIDIA GB200 NVL72:
72 GPUs in a single NVLink domain (130 TB/s bandwidth)
Functions as “one massive GPU” at rack scale
Uses Dynamo + TensorRT-LLM for disaggregated prefill/decode, dynamic scheduling, and KV cache routing
Benchmark results (DeepSeek-R1, 8K input / 1K output):
Interactivity TargetGB200 NVL72 vs H200vs MI355X
25 tokens/sec/user10x5.9x
60 tokens/sec/user24x11.5x
75 tokens/sec/userN/A28x
The NVL72 achieves interactivity levels competitors cannot reach at any throughput—e.g., 275 tokens/sec/user per GPU in a 28-GPU config, while MI355X peaks at 75 tokens/sec/user.
Tokenomics: More Expensive GPUs, Lower Token Costs
Despite higher upfront cost, GB200 NVL72 drastically lowers cost per token.
NVIDIA Generational Comparison (vs H200)
(Based on CoreWeave list pricing)
MetricGB200 NVL72H200
Normalized Cost per GPU-Hour$10.50$6.31
Price Ratio1.67x1.0x
Performance Delta (mid-range)~20x1.0x
Relative Cost per Token1/12th1.0x
Competitive Comparison (vs AMD MI355X)
(Based on Oracle Cloud pricing)
Metric (75 tokens/sec/user)GB200 NVL72MI355X
Normalized Cost per GPU-Hour$16.00$8.60
Performance Delta28x1.0x
Performance per Dollar15x1.0x
Relative Cost per Token1/15th1.0x
Counterintuitive but true: the “more expensive” platform is actually cheaper to operate because performance gains far outweigh cost differences.
Conclusion
The future of frontier AI lies in larger, more complex MoE models. Sparse scaling is one of the most practical paths to greater intelligence—elevating the importance of test-time compute and reasoning-style generation.
As models evolve, success depends less on raw GPU specs and more on platform-level design:
Interconnect & communication efficiency
Multi-node scalability
Software stack maturity
Ecosystem support & orchestration
High utilization under concurrency
Current trends suggest OpenAI, Meta, Anthropic, and others will continue down the MoE/reasoning path. If so, NVIDIA maintains a decisive edge—its platform is optimized precisely for these workloads.
AMD is developing rack-scale solutions (e.g., Helios), and gaps may narrow in 12 months. Google’s TPU also offers rack-scale design, but its performance on third-party models remains unclear.
These performance differentials translate directly into business outcomes:
Lower cost per useful token
Higher revenue per rack
Ability to offer premium experiences at scale
A concrete example: 28x higher throughput per GPU unlocks new product tiers and complex functionalities—without linear hardware growth.
This is the new economics of AI inference—and it favors platforms built from the ground up for the MoE and reasoning era.
Reference:
From Dense to Mixture of Experts: The New Economics of AI Inference – Signal65

 Fear of God ESSENTIALS Hoodie Review: Mi83 人气#fashion
Fear of God ESSENTIALS Hoodie Review: Mi83 人气#fashion The Derby of San Francisco Style 300 Cha108 人气#fashion
The Derby of San Francisco Style 300 Cha108 人气#fashion Why the Derby of San Francisco Classic S127 人气#fashion
Why the Derby of San Francisco Classic S127 人气#fashion Romaoss Launches "Rebirth Plan," in Talk65 人气#tech
Romaoss Launches "Rebirth Plan," in Talk65 人气#tech


 WeChat
WeChat douyin
douyin